Clustering
Cluster analysis is an unsupervised learning technique that is able to group instances into clusters based on the distinct characteristics of the data points. Unsupervised learning operates on unlabeled data and focuses on learning from input without human supervision. The goal of clustering is to divide unlabeled objects into meaningful groups where items in each subset are similar to each other rather than to instances in other subsets. This method is often used for data exploration, facilitating the identification of underlying patterns within the dataset that are not immediately obvious. 1,2
K-Means
K-Means is a simple non-parametric clustering algorithm used for partitioning samples into separated clusters of equal variance. The algorithm begins by randomly selecting K observation instances as the initial centroids, then proceeds by assigning each observation to the cluster whose centroid is closest to it. Different distance-based methods can be employed to calculate the respective distances between datapoints. The centroids are then recomputed as the average of the observations allocated to the cluster. This process is repeated until the assignment of observations to clusters no longer changes significantly, or after a fixed number of iterations. The K parameter denotes the number of clusters that are formed. 1,2
Use the K-Means clustering function by browsing in the top ribbon:
| Analytics \(\rightarrow\) Clustering \(\rightarrow\) K-Means |
Input
Data matrix with training set data. String columns are not taken into account in the algorithm implementation since K-means does not allow the use of nominal (categorical) input.
Configuration
| Number of centroids | Specify an integer representing the number of centroids (K) to generate, coresponding to the number of clusters that form (default value: 3). |
| Number of iterations | Specify the maximum number of times the algorithm runs to converge with different centroids (default value: 100). |
| Distance method | Select the metric used to calculate distances between data points. Three options are available for selection: - Manhattan/L1: Sum of the absolute differences between coordinates of instances pairs, - Euclidean/L2: Square root of differences between coordinates of instances pairs, and - Cosine: Uses cosine distance to determine how two features are oriented relative to each other, based on the angle between the vectors rather than their magnitude. |
| Initialization | Select the method used for the initialization. Two options are available for selection: - Random: Cluster centroids are randomly selected for initialization, and - KMeans++: Improved cluster initialization technique that uses a heuristic to find centroid seeds. For more information on K-means++ see in Arthur et al.3. |
| Number of threads | Isalos supports multi-threading for K-Means. Specify the number of threads to use for computation (default value: 100). |
| RNG Seed | Select an integer as seed to get reproducible results. The option to select a time-based random number-generated seed is available by clicking on the Time Based RNG Seed checkbox. |
Output
A data matrix listing the characteristics of each centroid and cluster assignment information is presented.
Example
Input
In the left-hand spreadsheet of the tab import the data matrix. In case that categorical features are included in the input data matrix, an error message appears: “K-means does not allow the use of nominal (categorical) input. To proceed please remove column(s)”.
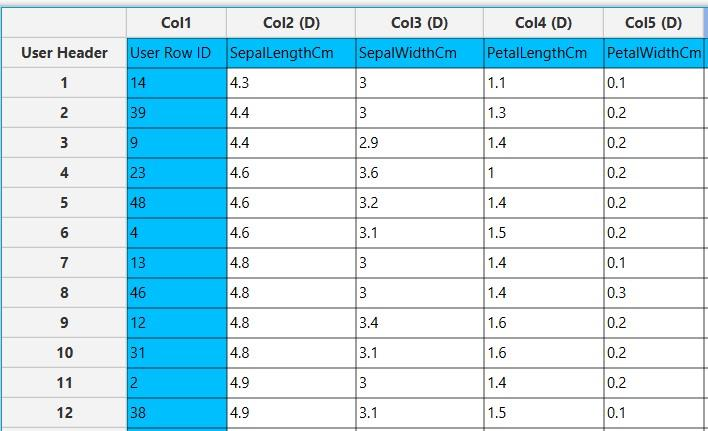
Configuration
- Select
Analytics\(\rightarrow\)Clustering\(\rightarrow\)K-Means. - Select the
Number of clusters[1], and theNumber of iterations[2] the algorithm will run to converge. - Select the
Distance method[3] that determines the centroid closest to an instance and determine theInitializationmethod [4]. - Select the
Number of threadsto choose the single-threaded or multi-threaded version of the algorithm [5]. - Select an RNG Seed for reproducible results or a random number generated
Time Based RNG Seed[6]. - Click on the
Executebutton [7] to apply the training algorithm on the input columns.

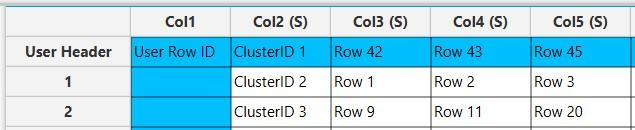
Output
In the right-hand spreadsheet of the tab the output data matrix with the centroid and cluster assignment information is presented. The first section lists the centroids of each cluster with an identifier [1] and presents the average value of the points that are assigned to each respective cluster for all the numerical variables in the dataset. In the second section [2] the data points assigned to each cluster are presented horizontally.

Application on external set
You can apply the trained K-Means model to any external (test) data using the Existing Model Utilization function:
- Import the external data in the left-hand spreadsheet of the tab. Include the same columns used to build the K-Means model.
- Select
Analytics\(\rightarrow\)Existing Model Utilization. Select the K-Means model [1] and click on theExecutebutton [2].

- Inspect the results in the right-hand spreadsheet of the tab.
DBSCAN
DBSCAN is a density-based clustering algorithm that groups together data points that are close to each other based on a specified distance metric, while marking points that lie alone in low-density regions as outliers (noise). Unlike algorithms such as k-means, DBSCAN does not require predefining the number of clusters, making it well-suited for exploratory data analysis where the underlying cluster structure is unknown.
There are are two key parameters in this algorithm:
- Epsilon: This is a numeric value that defines the radius of the neighborhood around a data point. Two point are set to be neighbors if the distance between them is less than eps. Choosing the correct value for this parameter is vital as a small Epsilon will result in a lot of outliers and a large Epsilon will merge clusters together.
- Min Points: This is an integer value that specifies how many points are required in a neighborhood for that to be characterized as dense. A genera rule is to set the Min Points parameter to k + 1 where k is the dimensionality of the feature space.
DBSCAN offers several advantages that make it a powerful and flexible clustering method. It can automatically determine the number of clusters based on the data’s density distribution, eliminating the need for manual input or prior assumptions. The algorithm can identify clusters of arbitrary shape and size, which is especially useful for complex or non-spherical data distributions. Moreover, DBSCAN is robust to outliers and noise, effectively separating them from meaningful cluster structures. It also performs well on datasets with varying cluster densities and does not require feature scaling to a specific range, though normalization can still improve performance.
Use the DBSCAN clustering function by browsing in the top ribbon:
| Analytics \(\rightarrow\) Clustering \(\rightarrow\) DBSCAN |
Input
Data matrix with training set data. Numerical and categorical columns are allowed. Differences in values in categorical columns are treated as 0/1.
Configuration
| Epsilon | Specify a positive double value representing the radius of each neighborhood. Default value is set to 0.5 |
| Min Points | Specify an integer value that represents the minimum number of points that have to be inside an Epsilon neighborhood for that neighborhood to be labeled as dense. |
Output
Cluster assignment information is presented.
Example
Input
In the left-hand spreadsheet of the tab import the data matrix with the data points that are to be clustered.
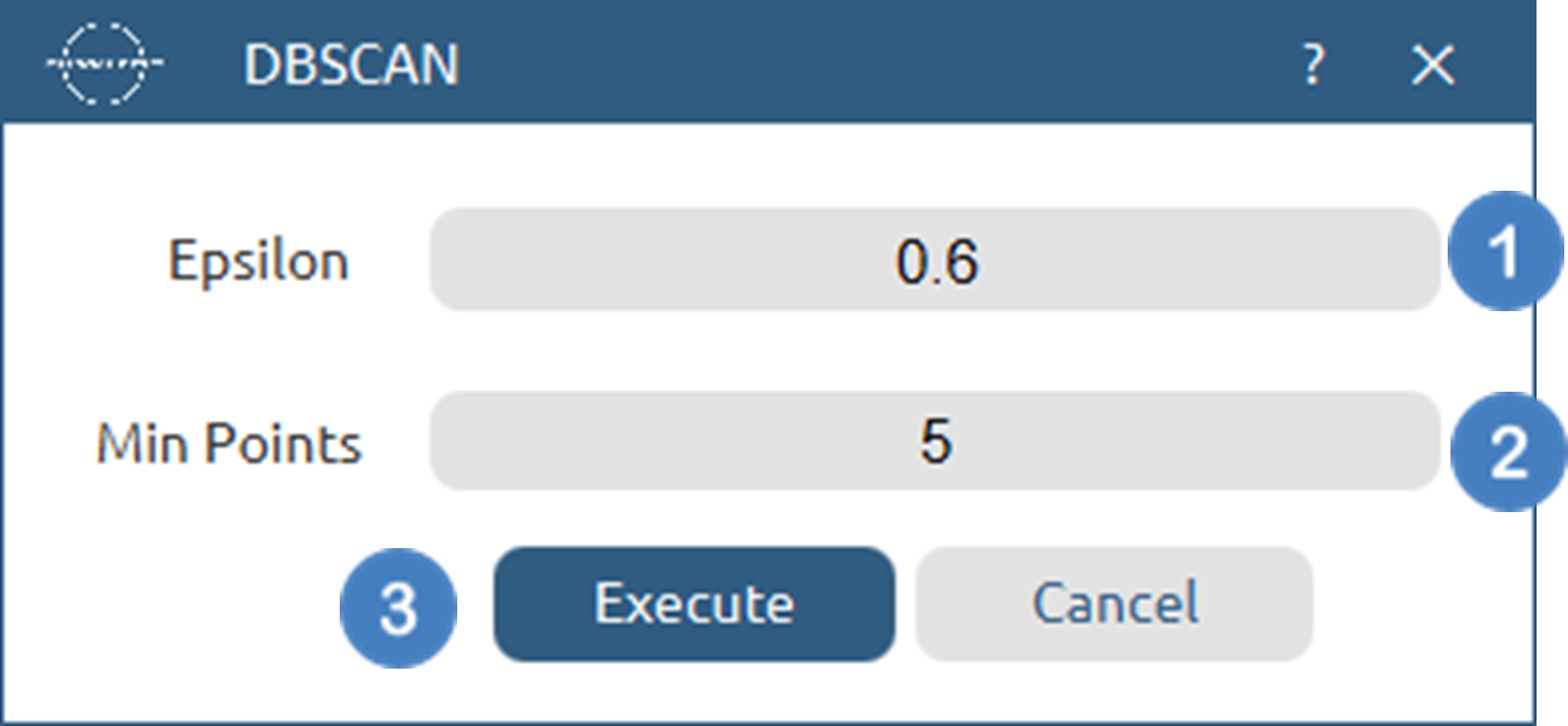
Configuration
- Select
Analytics\(\rightarrow\)Clustering\(\rightarrow\)DBSCAN. - Select the value for
Epsilon[1] - Select the
Minimum Points[2] that should exist in a region for that to be labeled as dense. - Click on the
Executebutton [3] to apply the algorithm on the input columns.
Output
In the right-hand spreadsheet of the tab the output data matrix with the cluster assignment information is presented where data points assigned to each cluster are presented horizontally.

✧ Tips
- As calculations of Euclidean distances are performed, consider scaling the data beforehand using a Normalizer function.
- The K-Means algorithm requires the number of clusters to be specified. Its performance is highly influenced by the initialization of the centroids and the selection of K.
See also
The model generated by any of the K-Means clustering algorithm can be applied to any input data through the Existing Model Utilization function (e.g., a K-means model trained from the training set data of a machine learning model can be applied to the test/external set data).
References
- Witten Ian H and Frank, Eibe and Hall, Mark A and Pal CJ. Data Mining: Practical Machine Learning Tools and Techniques. Fourth. Morgan Kaufmann; 2011. https://doi.org/10.1016/C2009-0-19715-5.
- Murphy KP. Machine Learning: A Probabilistic Perspective. The MIT Press; 2012. 10.5555/2380985.
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding. In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms; SODA ’07; Society for Industrial and Applied Mathematics: USA, 2007; pp 1027–1035. 10.5555/1283383.1283494.
- Ester, Martin, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. “A density-based algorithm for discovering clusters in large spatial databases with noise.” In kdd, vol. 96, no. 34, pp. 226-231. 1996. 10.5555/3001460.3001507.
- Schubert, Erich, Jörg Sander, Martin Ester, Hans Peter Kriegel, and Xiaowei Xu. “DBSCAN revisited, revisited: why and how you should (still) use DBSCAN.” ACM Transactions on Database Systems (TODS) 42, no. 3 (2017): 1-21. 10.1145/3068335.
Version History
Introduced in Isalos Analytics Platform v0.1.18
Instructions last updated on June 2024